MacMind
A transformer neural network in HyperTalk
Free and open source. HyperCard 2.0 or later. System 7 through Mac OS 9.
Real Transformer, Real Hardware
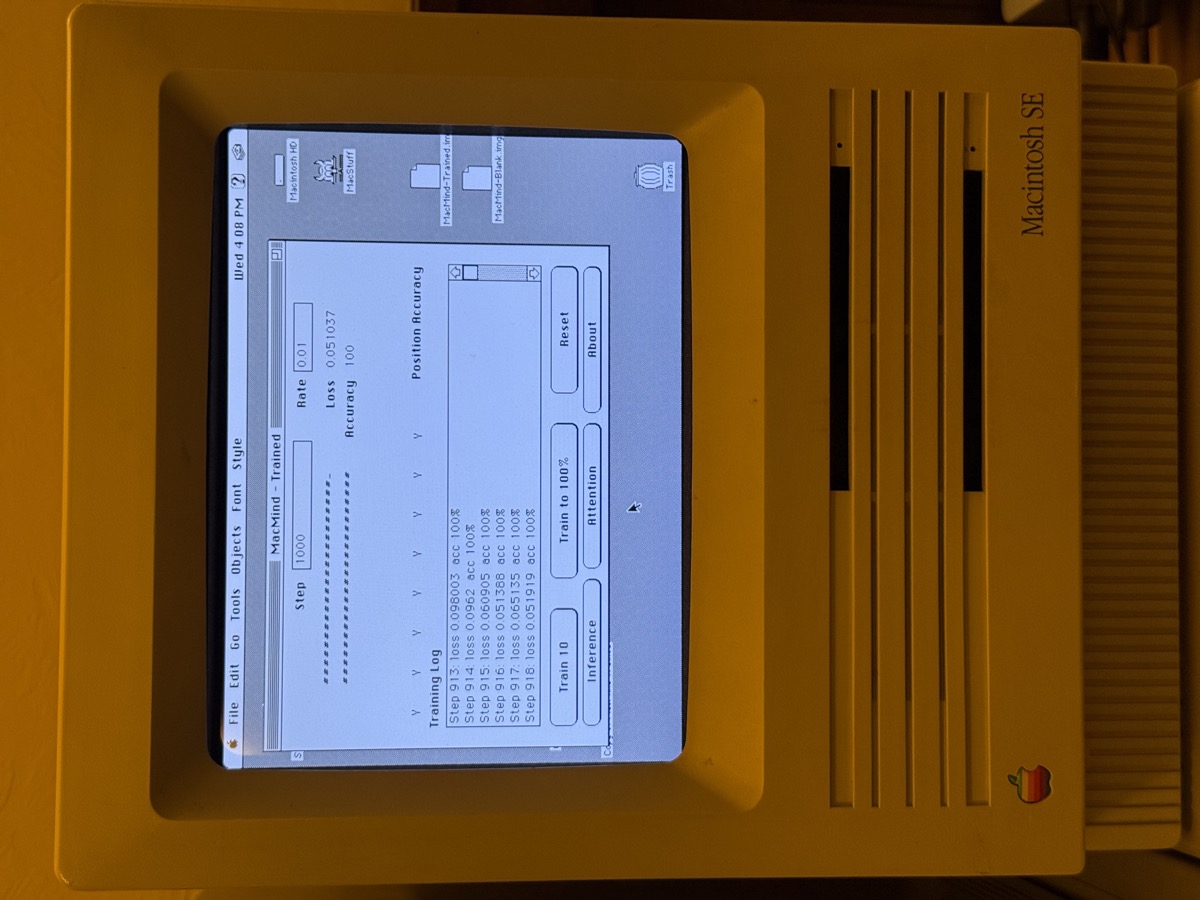
1,216 parameters. Token embeddings, positional encoding, self-attention, cross-entropy loss, full backpropagation, and stochastic gradient descent. The same architecture behind modern AI, running on a 68k processor from 1989. Trained on a Macintosh SE/30 overnight.
Everything Is Inspectable
Every line of the neural network is written in HyperTalk. Option-click any button and read the actual math. Change the learning rate, swap the training task, resize the model — all from within HyperCard's script editor. No compiled code. No external libraries. No black boxes.
Learns the FFT Butterfly
The model learns the bit-reversal permutation — the opening step of the Fast Fourier Transform — from random examples. It discovers the positional pattern purely through self-attention and gradient descent. After training, the attention map reveals the same butterfly routing structure that Cooley and Tukey published in 1965.
Train It Yourself
Download the blank stack and watch the model learn in real time. Click Train 10 for short runs, or open the Message Box and type trainN 1000 for a long session. Progress bars, per-position accuracy, and a training log update as the model converges.
Persistent Weights
All 1,216 weights are stored as comma-delimited numbers in hidden HyperCard fields. Save the stack, quit, reopen it: the trained model is still there, still correct. The intelligence lives inside the file.
The Engine With the Hood Up
The same process that trained MacMind — forward pass, loss, backward pass, weight update, repeat — is what trained every large language model that exists. The difference is scale, not kind. MacMind has 1,216 parameters. GPT-4 has roughly a trillion. The math is identical.
Requirements
Minimum: HyperCard 2.0 or later, System 7, 1 MB RAM, any 68000 or later processor.
Tested on: HyperCard 2.1, System 7.6.1, Macintosh SE/30 (68030, 4 MB RAM).
Also runs on: Mac OS 8, Mac OS 9, and Mac OS X Classic Environment through 10.4 Tiger on PowerPC. Works in Basilisk II, SheepShaver, and Mini vMac.